This article explains how LVM snapshots work and what the advantage of read/write snapshots is.
We will go through a simple example to illustrate our explanation.
First, create a dummy device that we will initialize as a PV:
/dev/loop0 lvm2 a-- 1.00g 1.00g
We now have a 1GB LVM2 Physical Volume.
vg0 1 0 0 wz--n- 1020.00m 1020.00m
lv0 vg0 -wi-a---- 400.00m
We now have a Volume Group vg0 and a 400MB Logical Volume lv0. Let’s see what our device mapper looks like
We have a single device vg0-lv0, as expected.
Let’s take a snapshot of our Logical Volume:
lv0 vg0 owi-a-s-- 400.00m
snap1 vg0 swi-a-s-- 120.00m lv0 0.00
We’ve created a 30 extents (120MB) snapshot of lv0 called snap1.
Let’s take a look at our device mapper:
vg0-snap1-cow: 0 245760 linear 7:0 821248
vg0-lv0: 0 819200 snapshot-origin 252:2
vg0-snap1: 0 819200 snapshot 252:2 252:3 P 8
This is interesting. We’d expect to see two devices. Instead, we have four. Let’s draw the dependencies:
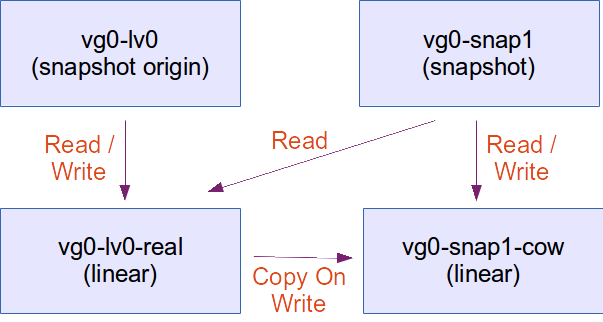
LVM snapshots explained
We can see that LVM renamed our vg0-lv0 device as vg0-lv0-real and created a new vg0-lv0 device. The user has now transparently switched to using vg0-lv0.
A new device named vg0-snap1-cow is the device of size 30 extents (120MB) that will hold the contents of the snapshot.
A new device named vg0-snap1 is the device that the user will interact with.
Reading from the original volume
The user reads from vg0-lv0. The request is forwarded and the user retrieves data from vg0-lv0-real.
Writing to the original volume
The user writes to vg0-lv0. The original data is first copied from vg0-lv0-real to vg0-snap1-cow (This is why it’s called COW, Copy On Write). Then the new data is written to vg0-lv0-real. If the user writes again to vg0-lv0, modifying data that has already been copied to vg0-snap1-cow, the data from vg0-lv0-real is simply overwritten. The data on vg0-snap1-cow remains the data that was valid at the time of the creation of the snapshot.
Reading from the snapshot
When the user reads data from vg0-snap1, a lookup is done on vg0-snap1-cow to see if that particular piece of data has been copied from vg0-lv0-real to vg0-snap1-cow. If that is the case, the value from vg0-snap1-cow is returned. Otherwise, the data from vg0-lv0-real is returned. The user effectively sees the data that was valid at the time of creation of the snapshot.
A few important things to note:
- The snapshot is empty at creation, whatever size it is. This means that the creation of a snapshot is immediate and invisible to the user.
- The snapshot will hold a copy of the original data, as the original data is modified. This means that the snapshot will grow over time. Therefore, it is not necessary to make a snapshot as big as the original volume. The snapshot should be big enough to hold the amount of data that is expected to be modified over the time of existence of the snapshot. Creating a snapshot bigger than the original volume is useless and creating a snapshot as big as the original volume will ensure that all data on the original volume can be copied over to the snapshot.
- If a snapshot is not big enough to hold all the modified data of the original volume, the snapshot is removed and suddenly disappears from the system, with all the consequences of removing a mounted device from a live system.
- A volume that has one or more snapshots will provide much less I/O performance. Remove the snapshot as soon as you’re done with it.
Writing to the snapshot
With LVM2, as opposed to LVM1, the snapshot is read-write.
When the user writes to vg0-snap1, the data on vg0-snap1-cow is modified. In reality, what happens is that the a lookup is done to see if the corresponding data on vg0-lv0-real has already been copied to vg0-snap1-cow. If not, a copy is done from vg0-lv0-real to vg0-snap1-cow and then overwritten with the data the user is trying to write to vg0-snap1. This is because the granularity of the data copy process from vg0-lv0-real to vg0-snap1-cow might be bigger than the data the user is trying to modify. Let’s imagine that data is being copied from vg0-lv0-real to vg0-snap1-cow in chunks of 8KB and the user wants to modify 1KB of data. The whole chunk is copied over to the snapshot first. Then the 1KB are modified.
A second write to the same data will result in simply overwriting data in vg0-snap1-cow.
Removing an LVM snapshot
The following command will remove the snapshot:
- This operation is very fast because LVM will simply destroy vg0-snap1-cow, vg0-lv0 and vg0-snap1, and rename vg0-lv0-real to vg0-lv0.
- All data that has eventually been written to the snapshot (through vg0-snap1) is LOST.
Merging a snapshot
The following command will merge the snapshot:
lv0: Merged: 100.0%
Merge of snapshot into logical volume lv0 has finished.
Logical volume "snap1" successfully removed
- The merge will start immediately if the filesystems in the original volume and in the snapshot are unmounted (i.e. if the volumes are not in use), otherwise the merge will start as soon as both filesystems are unmounted and one of the volumes is activated. This means that if a merge of the root filesystem is planned, it will happen after a reboot, as soon as the original volume is activated.
- This operation can take time, because data needs to be copied from the snapshot to the original volume.
- As soon as the merge begins, any read-write operation to the original volume is transparently redirected to the snapshot that is in the process of being merged. Therefore, the operation is transparent to the user who thinks he’s using the merged volume. This means that as soon as the merge begins, users interact with a volume that contains the data at the time of the creation of the snapshot (+ data that has eventually been written to the snapshot since then).
Benefits of read-write snapshots
Snapshots are of course very useful to make a consistent backup of a volume. The backup will be performed on vg0-snap1, reading data either from vg0-lv0-real or from vg0-snap1-cow if the data has been modified since the creation of the snapshot. This allows for a consistent backup of the volume at a certain point in time, without taking the volume offline.
But this can be done with read-only snapshots. So what are read-write snapshots useful for ?
Read-write snapshots (also called branching snapshots because of the fact that they create different versions of the data, a bit like a version control branch) are useful for virtualization, sandboxing and virtual hosting:
Read-write snapshots for sandboxing
Since the snapshot is read-write, you can use either the snapshot or the original volume to experiment on. Which one to choose will depend on the likeliness of having to revert. If you’re doing a system upgrade that is likely to succeed, take a snapshot and perform the upgrade on the original volume. If everything goes fine, remove the snapshot. If the upgrade fails and you need to revert, merge the snapshot.
If you’re booting a system every day at the same state (e.g. a Virtual Desktop Infrastructure situation), and you know you’re going to revert to the original state in the evening, let your user use the snapshot instead of the original volume. At the end of the day, just remove the snapshot. Every once in a while you’re going to merge because you want to keep a patch you’ve applied.
Read-write snapshots in virtualization
When using LVM volumes as storage backends for virtualization, a snapshot can be taken, effectively allowing the creation of a new VM. This VM can then evolve separately.
Read-write snapshots for virtual hosting
You can use an LVM volume to contain the image of a virtual machine. Then take a snapshot for one version of the VM, another snapshot for another modified version of the VM, etc. That way, the majority of the space of each VM instance resides in the original volume and the snapshots only contain the differences that are specific to a modified version of the VM or to an instance of the VM. This trades performance for space.
Nice article to understand snapshot..
Well explained and much needed to make things clear once and for all about LVM’s snapshots. Thanks a lot!
There seems to be a small disconnect here:-
Let’s say we create a snapshot of size 10 MB at 9.00 AM. The users keep changing the contents of original volume.
Let us assume that there is an addition of 5 MB data in next 15 minutes ( time after creating the snapshot ). As per this article, the contents in the original LV must have been copied to vg0-snap1-cow before any updation happens on vg0-lvo. That means the contents of vg0-snap1-cow have changed in the last 15 minutes, right ? My queries are:-
1. Imagine if some one tries to read the snapshot at 9.15 AM. What the user will see – the contents of vg0-snap1-cow at 9.00 AM or the modified contents at 9.15 AM ( addition of 5 MB ) ?
2. If the user sees the contents that were available at the creation time of snapshot then what is the use of copying the contents from vg0-lv0-real to vg0-snap1-cow after 9 AM ?
3. If the user sees the contents that were available at 9.15 AM then how can we say the data captured in snapshot is consistent ( from any backup perspective ) ?
Hi Rajesh,
To answer your questions #1 and #2 (#3 does not apply):
1) The user sees the contents as they were at 9 AM.
2) The contents are copied from vg0-lv0-real to vg0-snap1-cow a moment before they’re changed; then the new data is written in vg0-lv0-real. Therefore, vg0-snap1-cow contains effectively a copy of the old data — thatis, the data as it were before being changed.
The misunderstanding might come from the fact that LVM makes these snapshot dynamically, in a non-intuitive way. If you had to make a snapshot of a 400 Mb volume at 9 AM (hence freezing the contents of the volume as they were at that exact moment), you’d probably create an exact, byte-per-byte, static copy of the volume. This works well, but requires 400 Mb of additional space.
Instead, a LVM snapshot of the volume, at the moment it is made at 9 AM, takes zero space. Then, at 9:03 AM, the user wants to write some new files to the volume, changing 5 Mb of data. An instant before this happens, the 5 Mb of old data (that were going to be overwritten) are copied from the volume to the snapshot. Only afterwards the system writes the 5 Mb of the user’s new files onto the volume. Now the snapshot is 5 Mb in size — the size of the old data. From the point of view of the user, nothing special happened, and the volume has been updated with the new data.
Later, at 9:08 AM, other 2 Mb of new data (say, http logs) are going to be written on the volume. LVM silently copies the 2 Mb of the old data of the volume to the snapshot, then overwrites these 2 Mb of space with the new http logs. Now the snapshot is 7 Mb in size. And so on. The process continues until the space that was allocated for the snapshot (120 Mb in our article) is full, in which case the snapshot is destroyed. Otherwise, the snapshot can also be deleted manually at any moment. In either case nothing bad happens to the original volume, which has been functioning as usual.
Therefore, the snapshot effectively reflects the state of the volume at 9 AM. Note that this implies that a specific part of the volume is copied from the original volume to the snapshot only once; if the http logs written to disk at 9:08 AM are replaced by other files at 9:14, the former are not going to be transferred on the snapshot before being overwritten.
Basically, a LVM snapshot works like a delta backup: only blocks that differ are saved.
I am a little confused about « The data on vg0-snap1-cow remains the data that was valid at the time of the creation of the snapshot. », it seems to me vg0-snap1 only keep the data which are existed in vg0-lv0-real when the snapshot is created. But from your latest reply, seems vg0-snap1-cow are always changed if the there are data written to vg0-lv0-real, of course before it is full. Thanks.
Hi Gary,
vg0-snap contains no data: it’s the device with which the user interacts when they want to access the snapshot.
My explanation is somehow simplified as it mentions only the original volume and its snapshot. However, remember that there are four volumes, not two (as shown in the diagram published in the post). The user actually sees only vg0-lv0 and vg0-snap1. The other two, vg0-lv0-real and vg0-snap1-cow, are used by the system and are necessary to perform the Copy On Write mechanism.
vg0-snap1 will return either:
– data from vg0-lv0-real, if that particular piece of volume data has not changed since the snapshot;
– data from vg0-snap1-cow, if that particular piece of volume data has changed since the snapshot. In this second case vg0-snap returns the old data from the snapshot, not the latest, actual data.
In both cases, the user gets the data as it was at the moment of the creation of the snapshot.
The contents of a particular location of vg0-snap1-cow are changed only once, and this happens when new data is written (through vg0-lv0) in that particular location. In this case, the old data is copied (COW) on vg0-snap1-cow to be preserved, and the new data is written to vg0-lv0-real. If, some time later, other new data must be written to the same particular location, then the contents of vg0-lv0-real are simply overwritten; there’s no copy on vg0-snap1-cow beforehand. (The reason for this is obvious: if every time we overwrite the contents of vg0-snap1-cow, then it wouldn’t be a snapshot at a particular point in time.)