Comment j’ai déployé Ceph en PROD : épisode 3
La journée précédente s’est achevée sur l’ajout des monitors au sein du cluster Ceph, malheureusement sans succès.
Réseautons une dernière fois
Si vous avez bien lu l’épisode précédent, vous devriez vous souvenir du postulat final: « le datacenter 3 semble isolé par rapport au reste du réseau ». Toutefois, les serveurs présents dans le fameux datacenter étant tous accessibles en SSH, répondent au ping. En revanche, impossible pour les monitors présents sur place de rejoindre le cluster.
Afin d’obtenir de meilleures performances, les cartes réseaux des différents serveurs composant le cluster Ceph ont été configurées avec l’option « Jumbo Frame » activée. Cette option permet de transmettre des paquets IP de plus 1500 Bytes (la taille d’un paquet ip standard), en l’occurrence les cartes sont configurées pour transmettre des paquets de 9’000 Bytes. Pré-requis non négligeable, si vous voulez utiliser les jumbos frames entre deux équipements, TOUS les équipements réseaux éventuellement traversés par des « trames géantes » doivent supporter les paquets de 9’000 Bytes.
Vous l’aurez compris, le switch à l’entrée du datacenter 3 ne supporte pas les Jumbo Frames actuellement. Cette option n’a, de plus, pas pu être activée car celle-ci engendre le redémarrage du switch. Opération délicate compte tenu du fait que des installations de production sont directement reliées au dit switch.
La seule option viable actuellement fut la désactivation des trames géantes sur l’intégralité du cluster Ceph. Suite à cette manipulation, le troisième et dernier monitor fut intégré au quorum sans aucun problème. Les choses sérieuses peuvent commencer !
Au tour des OSDs
Notre cluster met actuellement à disposition la capacité de stockage incroyable de 0.00 GB, c’est tout à fait normal, il est pour l’instant uniquement composé de monitors.
[pastacode lang= »bash » manual= »%5Bcephdeploy%40CephAdmin%20clusterceph%5D%24%20ceph%20-s%0A%20%20%20%20cluster%20XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX%0A%20%20%20%20%20health%20HEALTH_ERR%0A%20%20%20%20%20%20%20%20%20%20%20%2064%20pgs%20are%20stuck%20inactive%20for%20more%20than%20300%20seconds%0A%20%20%20%20%20%20%20%20%20%20%20%2064%20pgs%20stuck%20inactive%0A%20%20%20%20%20%20%20%20%20%20%20%2064%20pgs%20stuck%20unclean%0A%20%20%20%20%20%20%20%20%20%20%20%20no%20osds%0A%20%20%20%20%20monmap%20e1%3A%203%20mons%20at%20%7BmonitorETL%3DXX.XX.XX.XX%3A6789%2F0%2CmonitorSTA%3DXX.XX.XX.XX%3A6789%2F0%2CmonitorUMA%3DXX.XX.XX.XX%3A6789%2F0%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20election%20epoch%206%2C%20quorum%200%2C1%2C2%20monitorETL%2CmonitorSTA%2CmonitorUMA%0A%20%20%20%20%20osdmap%20e1%3A%200%20osds%3A%200%20up%2C%200%20in%0A%20%20%20%20%20%20%20%20%20%20%20%20flags%20sortbitwise%2Crequire_jewel_osds%0A%20%20%20%20%20%20pgmap%20v2%3A%2064%20pgs%2C%201%20pools%2C%200%20bytes%20data%2C%200%20objects%0A%20%20%20%20%20%20%20%20%20%20%20%200%20kB%20used%2C%200%20kB%20%2F%200%20kB%20avail%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2064%20creating » message= » » highlight= » » provider= »manual »/]
Ajoutons notre premier serveur composé de 12 disque durs de 6TB chacun. Pour ce faire, la commande ceph-deploy suivante ajoute le disque dur souhaité au cluster Ceph :
[pastacode lang= »bash » manual= »ceph-deploy%20osd%20prepare%20%7Bserver-name%7D%3A%7Bdisk-name%7D%3A%7Bdisk-journal-name%7D » message= » » highlight= » » provider= »manual »/]
Voici un petit rappel de la composition en disques de chaque serveur :
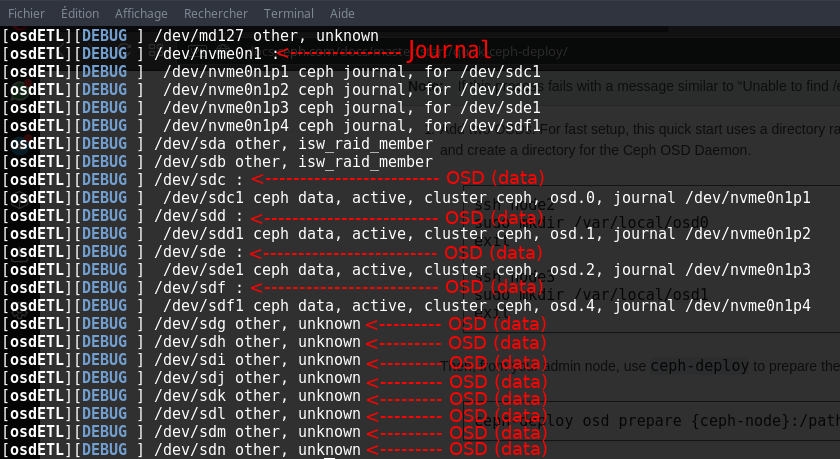
Liste des disques sur chaque serveur…
Les 12 disques durs (de sdc à sdn) stockent leurs journaux sur un SSD NVMe, ici appelé nvme0n1. Vous pouvez d’ailleurs voir que 4 disques font actuellement parti du cluster (sdc, sdd, sde et sdf) avec leurs journaux respectifs (nvme0n1p1,nvme0n1p2,nvme0n1p3,nvme0n1p4).
Ajoutons un cinquième disque au cluster à l’aide de la commande « ceph-deploy osd prepare » décrite plus haut:

Une fois le disque formaté et configuré par ceph-deploy, celui-ci est intégré au cluster :

Le cluster fait maintenant 27TB. Il reste à répéter l’opération pour les 31 disques restants.

Le compte est bon, 196TB d’espace brut et 36 disques présents dans le cluster. Vérifions l’attribution des disque au sein des serveurs OSD :
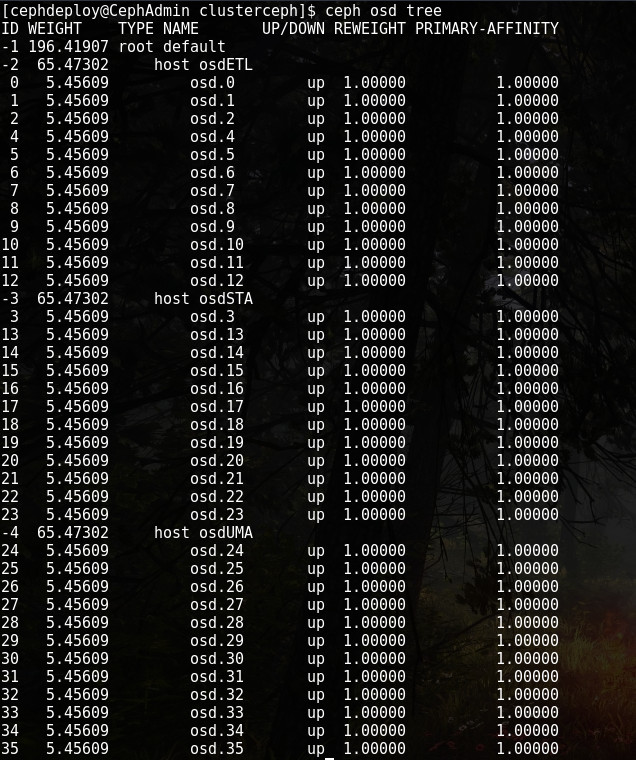 Chaque serveur est bien composé de 12 disques et Ceph a bien créé 3 serveurs.
Chaque serveur est bien composé de 12 disques et Ceph a bien créé 3 serveurs.
Les pools
Créons maintenant les pools requis pour l’utilisation de CephFS.
Un « pool » au sens Ceph est un regroupement de données accessibles via une méthode bien particulière. Ceph offre l’accès aux données stockées dans un « pool » via trois protocoles différents, le block storage, l’object storage ou via un file system (CephFS). Il est également possible de définir un niveau de réplication propre à chaque pool.
Dans le cas qui nous intéresse nous allons créer un pool en « replica 3 » qui sera accessible via CephFS, l’accès en mode file system donc. Pour ce faire la commande « ceph osd pool » s’utilise ainsi:
[pastacode lang= »bash » manual= »ceph%20osd%20pool%20create%20%7Bpool-name%7D%20%7Bpg-num%7D » message= » » highlight= » » provider= »manual »/]
J’ai donc créé le pool CephFS ainsi:
[pastacode lang= »bash » manual= »ceph%20osd%20pool%20create%20backup%201024″ message= » » highlight= » » provider= »manual »/]
Puisqu’il s’agit d’un pool CephFS, un deuxième pool doit être créé pour stocker les métadonnées des futurs fichiers stockés :
[pastacode lang= »bash » manual= »ceph%20osd%20pool%20create%20backup_metadata%201024″ message= » » highlight= » » provider= »manual »/]
« 1024 » est le nombre de groupes de placement compris dans le pool, cette valeur est calculée ainsi (choisir la puissance de deux la plus proche du résultat) :
(OSDs * 100)
Total PGs = -------------
Replicas
Un groupe de placement permet à Ceph de repartir les objets sur les différents OSD du cluster.
CephFS
Maintenant que les deux pools sont créés, nous pouvons initialiser CephFS. La première étape consiste à créer des serveurs « mds ». Les mds (metadata server) gèrent les métadonnées indispensables au bon fonctionnement de CephFS. Ces métadonnées sont stockées dans le pool créé précédemment portant le nom de « backup_metadata ».
Un mds peut être créé directement avec « ceph-deploy » comme suit :
[pastacode lang= »bash » manual= »ceph-deploy%20mds%20create%20%7Bhost-name%7D » message= » » highlight= » » provider= »manual »/]
Afin d’éviter tout SPOF (single point of failure), trois mds ont été créés. Un mds par serveur déjà utilisé comme monitor.
[pastacode lang= »bash » manual= »ceph-deploy%20mds%20create%20monitorSTA%0Aceph-deploy%20mds%20create%20monitorETL%0Aceph-deploy%20mds%20create%20monitorUMA » message= » » highlight= » » provider= »manual »/]
Actuellement, avec Ceph Jewel, les serveurs mds fonctionnent en actif-passif voir même en actif-passif-passif dans le cas présent. La documentation Ceph ne conseille pour l’instant pas l’utilisation de plusieurs mds actifs pour une utilisation en environnement de production. Les mds sont maintenant prêts à prendre en charge le pool CephFS :
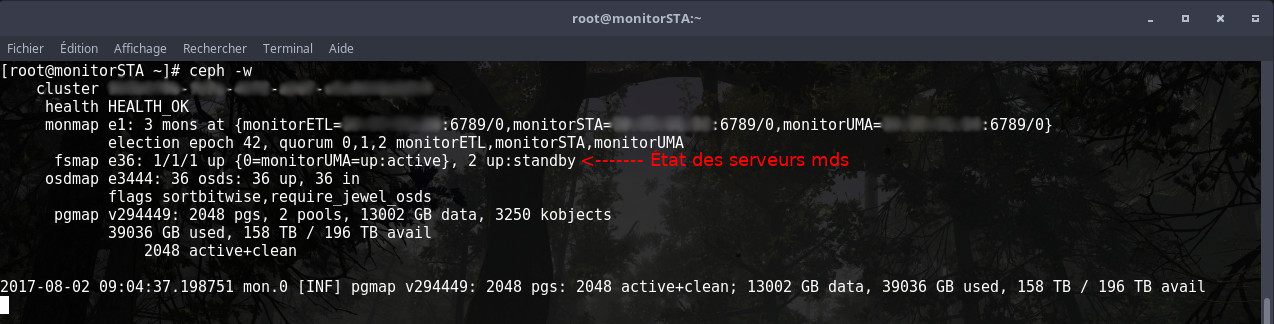
La capture d’écran ci-dessus montre que le serveurUMA est le mds actif actuellement. Deux autres serveurs mds sont actuellement « up » mais en « standby » prêts à prendre le relais si le serveur actif devait subir une avarie.
Créons sans plus tarder le système de fichier CephFS comme suit :
[pastacode lang= »bash » manual= »ceph%20fs%20new%20backup%20backup_metadata%20backup » message= » » highlight= » » provider= »manual »/]
Le système de fichiers qui s’appelle « backup » stocke ses métadonnées dans le pool « backup_metadata » et les données sont stockées dans le pool « backup ».


Laisser un commentaire
Participez-vous à la discussion?N'hésitez pas à contribuer!